
"我們的心智是嚴重的偏向因果的解釋,而不跟統計數字打交道。當我們的注意力轉到一個事件上去時,我們的記憶就替他找因果關係。" - Kahneman
第二部捷徑與偏見,說明我們的心智看待事物的盲點。其中比較有趣的是錨點與因果基率的誤判。
什麼是因果基率?一個很有趣的
case 我們先看看:
文清現年 35 歲政治世家出身,大學攻讀政治與中文兩門科系。學生時代非常關心社會公義,熱衷於舉行學生訴求抗議等活動,最近更去參加了反核遊行。
根據下列描述文清的現況,依照你認為的可能性排序:
- 文清是議員
- 文清在書店工作,也早起去公園健身
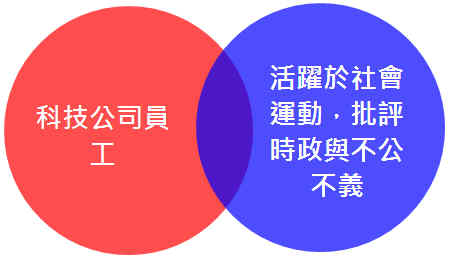
- 文清是科技公司員工
- 文清是房地產仲介
- 文清活躍於社會運動,批評時政與不公不義
- 文清是科技公司員工且活躍於社會運動,批評時政與不公不義
我們在紙上寫完心中的順序後,讓我們聚焦在這兩句:
3.文清是科技公司員工
6.文清是科技公司員工且活躍於社會運動,批評時政與不公不義
請問寫在紙上順序是 3>6
還是 6>3 呢?如果跟我一樣寫了順序 6 >3,就是犯了因果基率的誤判。文章開頭的三個圓圈的 Venn diagram,我們高中學習交集聯集等基礎統計就用到了。
Kahneman 藉由類似的實驗證明了系統二在判斷上的盲點:我們會聚焦在某人的表徵 (representativeness),而忽略機率以及對描述準確性的懷疑,如果我們把場景或描述拿來做預測工具時,輕率地用似是而非的判斷去替代機率,會嚴重影響我們的判斷。
也就是說,系統一很愛根據看到的敘述亂編故事,負責把關的系統二的懶惰是生活中的一個重要的事實,而表徵可以阻擋相當顯著的邏輯規則。我們真的太愛聽到因為…..所以發生….這種說法,而忘了去看看統計數據。極端的預期以及願意從很弱的證據中預期很少見的事件,兩這都是系統一的表現,我們的連結機制很自然的替極端的預測找出符合他的極端證據。
所以我學到了什麼?追查不良產品時常使用到的製作線別層別,了解是否特定生產線製作的產品不良率較高:工程師將不良率高批號的製作線別做了層分 :

如果換個角度看呢?統計各線總共製作批數與不良批數,計算不良率:


很明顯的發生了誤判!我們應該考量使用貝式定理,而不是因為有過個案妄下結論,我們應該拒絕因果基率,我們很容易以為自己得到了滿意的答案 : 我們使用了因果基率,只不過把統計事實給忽略了。
相關連結
貝氏定理(上) – Monty Hall 的三扇門
貝氏定理(下) – 99%的準確度
博客來 : 快思慢想
相關連結
貝氏定理(上) – Monty Hall 的三扇門
貝氏定理(下) – 99%的準確度
博客來 : 快思慢想

沒有留言:
張貼留言
Anything That's Worth Chatting